
Wat is het verschil tussen Machine Learning, Deep Learning en Artificial Intelligence?
Drie ‘Hot ITems’ in de BI & Analytics-wereld van nu zijn onmiskenbaar Artificial Intelligence (AI), Machine Learning (ML) en Deep Learning (DL). Wat betekenen deze termen eigenlijk en wat zijn de onderlinge verschillen?
Babylonische spraakverwarring
Er is nogal wat spraakverwarring rondom bovenstaande termen. De onduidelijkheid wordt mede veroorzaakt doordat veel softwareleveranciers en consultancybureaus deze hippe termen gebruiken om producten en diensten aan te bevelen die weinig met Artificial Intelligence of Machine Learning te maken hebben.
De beste manier om uit te leggen wat deze begrippen nou echt betekenen, is aan de hand van een voorbeeld. Daarom zal ik in dit blog steeds refereren aan één case waarbij steeds meer intelligente taken door machines worden overgenomen:
De case: op basis van een cv wordt besloten of een sollicitant wordt uitgenodigd voor een sollicitatiegesprek.
Regelgebaseerde expertsystemen
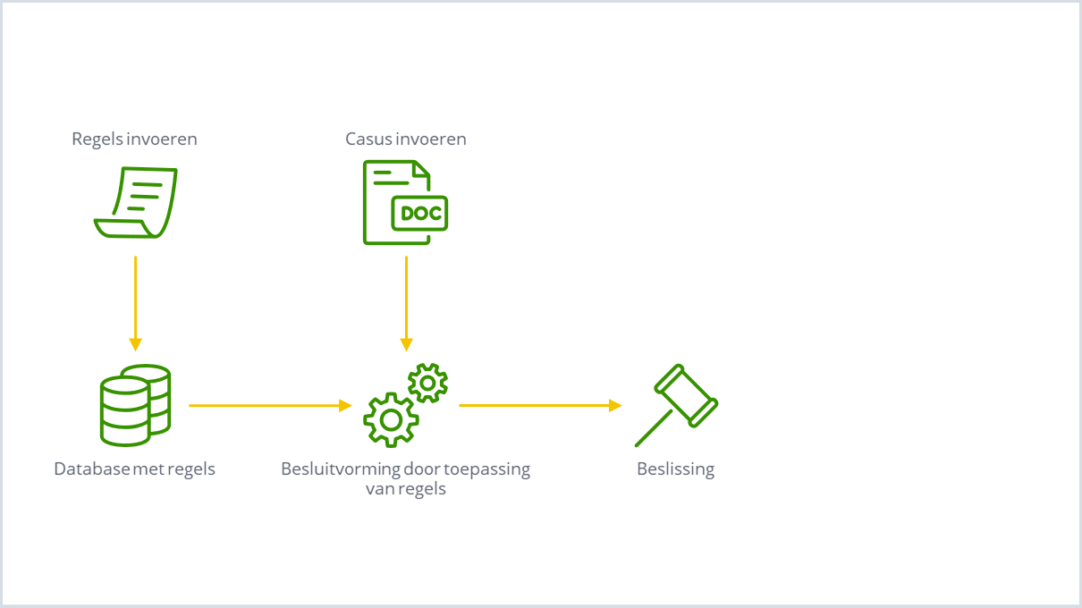
Al in de jaren tachtig van de vorige eeuw trachtten academici deze case te automatiseren door middel van zogenaamde regelgebaseerde expertsystemen. Een expertsysteem representeert en gebruikt specifieke menselijke kennis om een probleem op te lossen. Zo’n expertsysteem lijkt op een stemwijzer; op basis van regels en stellingen wordt een advies gegeven.
Het configureren van zo’n expertsysteem ging als volgt: een recruiter werd geïnterviewd en op basis van zijn antwoorden werden regels opgesteld. Een voorbeeld van zo’n regel is: ‘Als een vacature academisch denkniveau vereist, dan moet de sollicitant minimaal een diploma van een universiteit hebben behaald’. Deze regels werden softwarematig in een database opgeslagen.
Het beslissingsproces ging als volgt: het papieren cv werd handmatig omgezet in het juiste elektronische formaat. Als in het cv bijvoorbeeld stond ‘afgestudeerd aan de Universiteit van Amsterdam’, dan werd door een menselijke datapreparateur in het input-databestand ‘Academisch’ ingevuld in het veld ‘Opleidingsniveau’. Dit input-databestand werd als casus aangeboden aan het expertsysteem en een ‘Inference Engine’ paste de regels toe op de input en kwam met een output, namelijk een beslissing.
Expertsystemen draaiden uit op een flop. In complexe uitdagingen, waar mensachtige intelligentie vereist is, bleek het identificeren en vastleggen van regels onbegonnen werk. In een vakgebied waar expertkennis nodig is, zijn er niet alleen heel veel regels, er is ook altijd een uitzondering op de regel. Soms geeft een recruiter op basis van zijn intuïtie iemand die niet voldoet aan de sollicitatie-eisen het voordeel van de twijfel. Probeer deze intuïtie maar eens in een uitzonderingsregel te gieten. Daarnaast zijn subtiele verbanden tussen kenmerken en een beslissing vaak meerdimensionaal, en gaan ze het bevattingsvermogen van mensen ver te boven. Mensen zijn goed in staat om complexe beslissingen te nemen, maar kunnen vaak moeilijk in woorden of regels aangeven waaróm ze voor een bepaalde optie kiezen, zoals dat nieuwe huis, die nieuwe baan of die nieuwe partner. Kortom: voor simpele en afgebakende problemen zijn regelgebaseerde systemen wel toe te passen, maar voor complexere intelligentie heb je technieken nodig waaraan je niet alles letterlijk hoeft te vertellen, maar die zelf kunnen leren.
Machine Learning (ML)
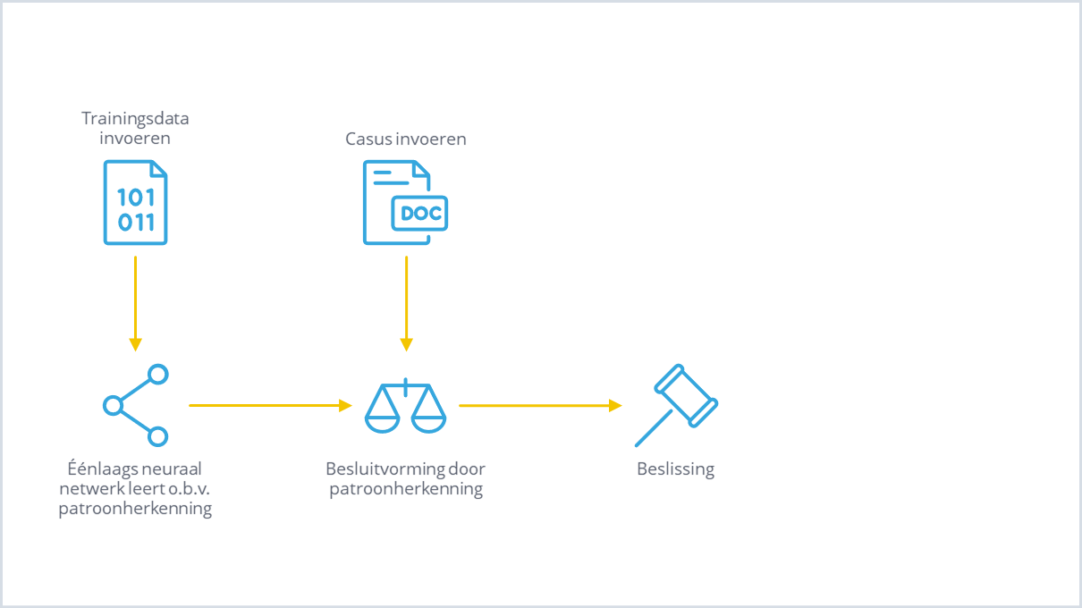
In het begin van deze eeuw ontstond er genoeg computercapaciteit om praktische computertechnieken te ontwikkelen die enorme hoeveelheden data konden verwerken. Op basis van statistische methoden konden conclusies uit deze data worden getrokken. Dit soort systemen kon met minimale interventie van menselijke experts zelf beslissingsvaardigheden aanleren. Deze lerende machines, ook wel Machine Learning (ML) genoemd, waren niet regelgebaseerd, maar bestonden uit een neuraal netwerk, gebaseerd op de werking van menselijke hersenen. In plaats van handmatig regels in het systeem te stoppen, werd het systeem gevoed met voorbeelden. Op basis van deze trainingsdata werden de neuronen in het neuraal netwerk steeds meer gefinetuned.
De basis van Machine Learning is patroonherkenning: ‘Als het lijkt op een vis en zwemt als een vis, dan moet het wel een vis zijn’. Het lerende systeem wordt daarom getraind met ‘kenmerken’ van vissen, bijvoorbeeld kieuwen, waardoor het systeem kan besluiten of voorspellen dat een input-plaatje van een visachtig dier waarschijnlijk een vis is, als het visachtige kenmerken heeft.
Het configureren van zo’n Machine Learning-systeem in de sollicitatiecase gaat als volgt: een recruiter geeft aan welke kenmerken van een cv een indicatie zijn voor het wel of niet uitnodigen van een sollicitant. Het Machine Learning-algoritme gaat vervolgens op basis van grote hoeveelheden trainingsdata (echte cv’s met echte sollicitatiecases) een steeds betere relatie leggen tussen deze kenmerken van het cv en een beslissing om iemand wel of niet uit te nodigen. Het bepalen welke ‘kenmerken’ van de inputdata een relatie hebben met de ‘output’, was aanvankelijk nog volledig mensenwerk. Al snel daarna werden er algoritmes ontwikkeld, waarmee het mogelijk werd machines zelf ook kenmerken te laten herkennen.
Het beslissingsproces gaat in dit voorbeeld als volgt: het papieren cv wordt handmatig omgezet in het juiste elektronisch formaat. Dit input-databestand wordt aangeboden aan het Machine Learning-systeem. Sommige neuronen worden door de inputdata of andere neuronen getriggerd, andere juist niet, en uiteindelijk komt de laatste neuron met een output, namelijk een beslissing.
Met Machine Learning was het niet meer nodig om zelf duizenden regels in te voeren, maar de performance van de besluitvorming van deze simpele uit één laag bestaande, neurale netwerken bleek ontoereikend voor echt indrukwekkende uitdagingen, zoals een zelfrijdende auto. Zo kan het Machine Learning-algoritme niet goed omgaan met uitzonderingen op de regel. Soms is een dier dat heel veel kenmerken heeft van een vis, zoals een walvis, toch geen vis. Een stemwijzer gebaseerd op machine learning in plaats van regelgebaseerde stellingen geeft je daarom minder vaak de reactie: ‘Huh?’.
Deep Learning (DL)
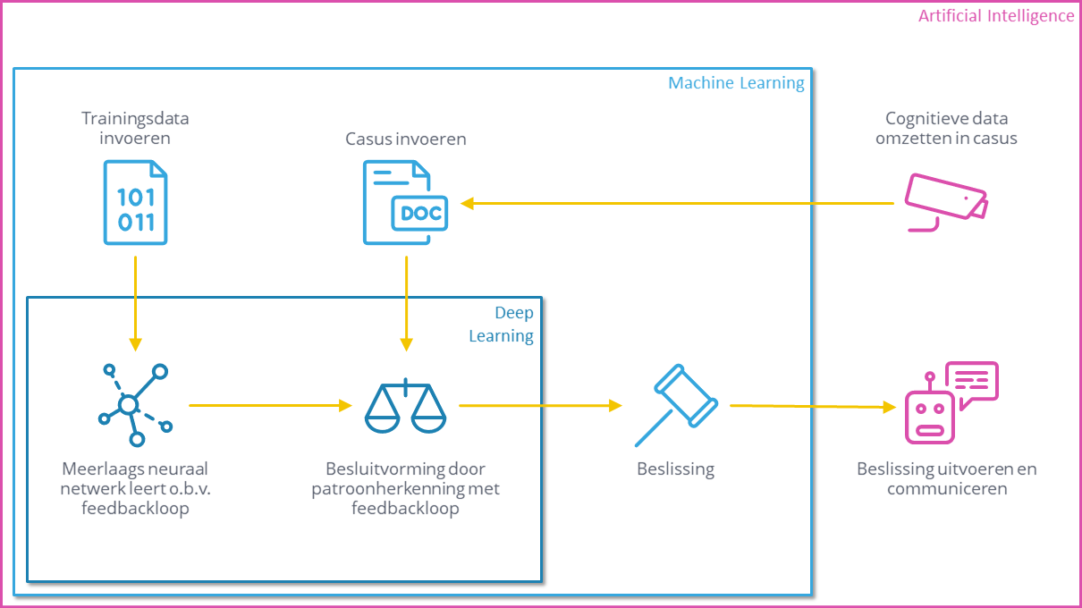
Machine learning-algoritmen die aan zeer intellectuele uitdagingen kunnen voldoen, maken gebruik van neurale netwerken met ‘diepere’ lagen. In elke laag wordt door middel van recursieve leeralgoritmes trapsgewijs geleerd. Een voorbeeld van zo’n algoritme is het ‘backpropagation algoritme’. Backpropagation bevat een feedbackloop en stelt Deep Learning in staat om zelfstandig te leren van eigen fouten en deze zelfstandig te herstellen. Met Deep Learning kun je robuustere oplossingen creëren dan met traditionele Machine Learning. Hierdoor kan het systeem beter omgaan met ontbrekende data of zelfs verkeerde input. In de echte wereld, met echte intellectuele uitdagingen, waarin slechte datakwaliteit helaas een gegeven is, komt dit goed van pas.
Een andere reden dat Deep Learning een betere performance heeft dan Machine Learning, is dat het veel effectievere en abstractere kenmerken kan ontdekken. In het sollicitatievoorbeeld bepaalt Deep Learning zijn beslissing niet alleen op basis van het kenmerk: ‘welke school heeft de sollicitant gevolgd’, maar vertaalt hij dit simpele kenmerk naar het effectievere kenmerk: ‘wat voor soort denkvermogen heeft de sollicitant’. Het kan zelfs zo zijn dat Deep Learning bepaalde kenmerken vindt die tegen alle menselijke intuïtie indruisen, maar die wel een zeer hoog voorspellende waarde hebben. Het zou bijvoorbeeld door een onnavolgbaar causaal verband zo kunnen zijn dat de maand van het geboortejaar iets zegt over de kans op succes van de sollicitant als deze eenmaal is aangenomen.
Deep Learning kan ook beter omgaan met uitzonderingen die in de echte complexe wereld nou eenmaal de regel zijn. Het Deep Learning-algoritme kan bijvoorbeeld adviseren dat iemand die niet voldoet aan de opleidingseisen, toch moet worden uitgenodigd voor een gesprek, omdat deze andere veelbelovende combinaties van kwalificaties heeft die zelfs een ervaren recruiter niet kan overzien.
Deep Learning is een effectieve vorm van Machine Learning. Het is een algoritme dat onze intelligente vermogens versterkt, maar het is geen autonome vervanging voor menselijke intelligentie. Met Deep Learning komen autonome Artificial Intelligence-machines die écht intelligent gedrag in de echte wereld kunnen vertonen, wel binnen handbereik.
Artificial Intelligence (AI)
Artificial Intelligence-robots, ook wel Intelligent Agents genoemd, kunnen zélf intelligent handelen en zijn in staat tot autonome mens-machine-interactie. Deze systemen kunnen niet alleen op menselijk niveau denken en acteren, ze kunnen ook op basis van menselijke communicatie leren.
Als je het sollicitatievoorbeeld met Deep Learning zou uitbreiden met systemen die kunnen communiceren en interacteren met de sollicitant, dan ontstaat échte Artificial Intelligence. Er zou een echt intakegesprek kunnen plaatsvinden tussen een sollicitant en een AI-agent, waarbij de communicatie twee kanten opgaat. Een Intelligent Agent kan met machinale zintuiglijke systemen als Natural Language Processing (NLP) en Computer Vision (CV) spraak en beeld opvangen en omzetten in data. Heeft het Deep Learning-algoritme een besluit genomen, dan kan deze robotachtige machine de beslissing ook uitvoeren en in natuurlijke taal communiceren.
Kortom: op deze manier kan de Intelligent Agent een intakegesprek met de sollicitant voeren, zelfstandig besluiten of de sollicitant wordt aangenomen en de uitkomst meteen ook mededelen. Dit alles zonder tussenkomst van een menselijke recruiter. Vooralsnog is een volledig autonome Artificial Intelligence-recruiter echter nog toekomstmuziek.
De komende jaren zal er vooral behoefte zijn aan recruiters die, naast hun eigen expertise, Deep Learning-hulpmiddelen effectief kunnen inzetten om nog betere beslissingen te nemen.
Over Jack Mooyer

De expertise van Jack is het datagedreven bestuurbaar maken van performanceverbetering en digitale transformatie. Hij heeft een passie voor datavisualisatie en business storytelling. Jack ontwikkelt hierbij nieuwe diensten zoals Transparent Machine Learning (TML) en Explainable Artificial Intelligence (XAI).

